Git Is Simpler Than You Think
It was about one year ago that we switched to Git. Previously, we used Subversion, through the Mac app Versions, which (rightly) holds an Apple Design Award.

I made the executive decision to leave our comfy world of Versions because it seemed clear that Git was winning the Internet. There was much grumbling from my teammates, who were busy enough doing actual work thank you very much.
But I pressed forward. We signed up for accounts on
Github. We learned how to type
'git push' and 'git pull'. We became
more confident. Git is just like any other source control system!
But it wasn’t long before one of our devs called me over to
look at a…situation.

It might as well have printed
PC LOAD LETTER. “Falling back to patching base and 3-way merge?”
That does not sound good at all. Or maybe it’s
completely normal? I type 'git status'.
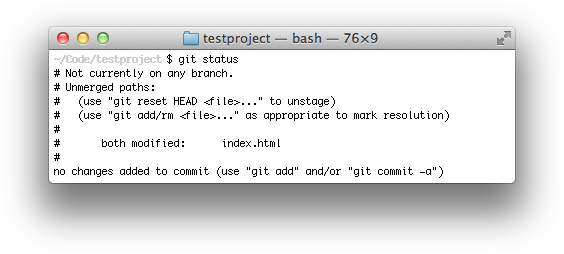
"Not currently on any branch?!" Now I’ve done it. We’re going to lose all the work he did today. Sweat is beading up on my forehead. Everyone is watching me to see if I can figure this out. After all, I got us into this mess.
Maintenance Required

Git is not a Prius. Git is a Model T. Its plumbing and wiring sticks out all over the place. You have to be a mechanic to operate it successfully or you’ll be stuck on the side of the road when it breaks down. And it will break down.
By now we all know how to drive Git. We learned it by typing “git tutorial” into Google. We studied guides, how-tos, cheat sheets.
Did you know the top result for “git tutorial” is this manpage on kernel.org? I will give you a gold star if you can read the whole thing without falling asleep.
So instead let’s pull over, open the hood up, and poke around.
The Basics
We’ll run through some basic commands to make a repository for our examples:
~$ mkdir mysite
~$ cd mysite
~/mysite$ echo "<title>All About Cats</title>" > index.html
~/mysite$ git init
~/mysite$ git add index.html
~/mysite$ git commit -m "First commit, added a title."
Now we have a git repository with one file and one commit, that is to say, one “version”. Let’s make a change and commit a second “version”:
~/mysite$ echo "<center>Cats are cute.</center>" >> index.html
~/mysite$ git commit -a -m "Added some text."
~/mysite$ open index.html
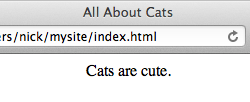
With me so far? Good.
The Repository
In Git there is no “client” and “server”. A repository is a repository, no matter if it’s on my machine, your machine, or Github.com.
Each repository lives in a single hidden folder called
.git. This is in stark contrast to Subversion which
infects your source tree with little .svn folders
everywhere.
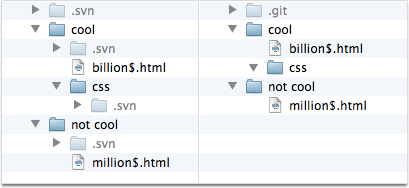
The .git “repository” is more than just
metadata and bookkeeping. It’s everything. All of
your source, all your changes, all your branches, all your commit
notes with swear words and in-jokes.
Go ahead, delete your index.html. As long as your
.git folder is intact, you can reconstruct it:
~/mysite$ rm index.html
~/mysite$ git checkout -- .
~/mysite$ ls
index.html
That would work even if you’d deleted a bunch of subfolders and huge files and whatever. Poof, it’s all back.
This explains why, when you “checkout”
(clone) the
Ruby on Rails
repository from Github, it takes a surprisingly long time.
You’re downloading onto your machine, into your new
rails/.git folder, the entire history of Ruby on
Rails. Every tiny change from David’s
initial commit
in 2004, it’s all sitting there on your disk.
This troubled me greatly at first. It’s so inefficient! My precious disk space!
And I can only say that disk space turned out to be a non-issue. But it took me some time. Maybe go take a walk outside, look at some trees, and come back later when you’ve accepted it.

User Interface
Now if you’re a curious person, you’ll likely say
“Wait. Go back. Where did you get the line ‘git checkout -- .' from? What does that even mean?”
To which I’ll respond, “I don’t know. I Googled it.”
And this brings us to Git’s greatest shortcoming, which is that Git’s terminology and syntax is fracking inscrutable.
Git’s overloaded, confusing language is absolutely the only part of it that sucks. They meant well. They chose words that sound familiar, like branch, checkout, tag, merge. But they often mean different things. Then you get the feeling that, as features were added and rethought, they just picked new unused words as they went along. Stage, fetch, rebase, remotes.
And because of Git’s explosive popularity, it’s a total Emperor-Has-No-Clothes situation. If you’re anything like me, you probably wondered why you were the only stupid person on the planet who didn’t intuitively get Git already. Even the beloved Github, though unaffiliated with Git, is much the same: as overwhelming as it is awesome.
Ultimately, when you look at Git, you don’t see a product that was “designed” holistically. It’s more like a collection of command-line utilities.
A Collection of Command-Line Utilities
This is a much better way to think about Git, and in fact this is what Git originally was. Git started life as a week-long project of Linus Torvalds to replace the old version control system they were using at the time to manage contributions to the Linux kernel.
You can’t design and build a fully-featured distributed version control system in a week. But you can design your data model. And it had better be really, really simple.
So what’s Git’s data model? To answer that, we need to
dig into that mysterious .git folder.
The So-Called “Object Database”
In mysite/.git, there is a subfolder called
objects. It should contain these folders and files
(edited for clarity):
~/mysite $ find .
./index.html
./.git
./.git/objects
./.git/objects/0d/0321f29f04f734e8d9873e34d9409fe115b496
./.git/objects/23/581023e9850ab48ec5ea6c4c9dcbeb82e76461
./.git/objects/2d/48a74575acab21d702f17f4ecce126b7e34ab0
./.git/objects/5b/853962ae2f41f608428968f8fffbf72f6cec2b
./.git/objects/87/48d7719d7321fad3739fce87ff84b6ded47e8b
./.git/objects/b1/a701e38645a3e60bc17a786cdd9062a15b5a21
These files with mangled-looking names are the
“objects” in our database for mysite. An
object can be either a commit, a tree, a
blob, or a tag. They’re compressed with
zlib, but you can
extract and examine them easily.
If we were to extract the object 23/5810…, we would
see:
<title>All About Cats</title>
…which is the old version of index.html! So
that’s a blob, that is, a particular version of one
file. If we extract the object 0d/0321…, we get:
commit 227tree 5b853962ae2f41f608428968f8fffbf72f6cec2b
parent b1a701e38645a3e60bc17a786cdd9062a15b5a21
author Nick Farina <n...@gmail.com> 1315106589 -0700
committer Nick Farina <n...@gmail.com> 1315106589 -0700
Added some text.
…which is a commit object (our last commit).
If you’re following along, you’ll notice that you
don’t have an object 0d/0321. Your commit will
have a different mangled name because your author name and email
won’t match mine. You see, the “mangled names”
of these files are
SHA1 Hashes
of their contents. If we computed the hash of the blob
<title>All About Cats</title>, we’d
get:
23581023e9850ab48ec5ea6c4c9dcbeb82e76461
Recognize that hash from the 23/5810… filename above?
Git chops off the first 2 characters of the hash and uses that as
a directory name, so we don’t end up with too many of these
little files in one place.
Git calls this “content-addressable” to sound fancy, but really it’s just a naming scheme. See, these “objects” have to be called something, so they might as well be named according to their contents.
Content-Addressable
Now if you’re reasonably paranoid, you may ask: “What if two different objects compute the same SHA1 hash code? Won’t this happen someday?”
It turns out you’ll never generate two of the same SHA1 hashes. The chances are miniscule. There’s room for all kinds of flowery comparisons like: You’d have to generate more hash codes than the number of stars in the universe before you’d get two of the same!
But my favorite is from Pro Git: “A higher probability exists that every member of your programming team will be attacked and killed by wolves in unrelated incidents on the same night.”

Commits
A commit represents a complete version of your code. Look again at the object file representing our last commit:
commit 227tree 5b853962ae2f41f608428968f8fffbf72f6cec2b
parent b1a701e38645a3e60bc17a786cdd9062a15b5a21
author Nick Farina <n...@gmail.com> 1315106589 -0700
committer Nick Farina <n...@gmail.com> 1315106589 -0700
Added some text.
This chunk of text contains enough hints to reconstruct the entire contents and history of our repository as it existed in this version.
The hash 5b8539… is the object containing the state
of our tree. A tree object is basically a manifest of
files and folders (simplified here):
blob 2d48a74575acab21d702f17f4ecce126b7e34ab0 index.html
blob b8ca7d5cba87d5123182375871234a76d6f78ff2 someotherfile.html <- example 2nd blob
tree 3182375871234a76d6f78ff2b8ca7d5cba87d512 Documentation <- example subfolder
This represents the filesystem structure at this point in time.
Cleverly, subfolders are represented by pointers to
other tree objects. Recursion! The “blob
objects” then contain the actual file data like
<title>All About Cats</title>.
To get the previous version of our repository, look at the
“parent” hash beginning with
b1a701 (again, different for you). This is the object
containing the previous commit.
So just by starting with our last commit object, we’ve explored the entire contents of our repository.
Branches
If we had a thousand objects in our database, it would be pretty hard to guess the hash of our last commit. So we’d better write it down somewhere.
~/mysite$ cat .git/refs/heads/master
0d0321f29f04f734e8d9873e34d9409fe115b496
This is what a branch is: it’s simply the hash of
the last commit scribbled down in a file. It’s a clue, a
starting point, sometimes called a tip because this
represents the tip of the iceberg that is the entire history of
the master branch.
And since you can have multiple branches in a repository, we should also remember which one we’re working on right now.
~/mysite$ cat .git/HEAD
ref: refs/heads/master
It’s forehead-slapping simple. Whenever you execute a Git
command, it first looks at .git/HEAD to see what our
working copy is supposed to be. And that contains a
reference to either a branch name or a commit object (that case is
a detached HEAD). If it’s a branch name, look at
the branch file to see what commit object it is. Then open up the
commit object to find all the trees and blobs and parents and
it’s
turtles all the way down.

Uniqueness
One last thing to ponder. Our objects folder contains
6 files. Three for the first version’s commit object, tree,
and blob. And three again for the last version’s commit
object, tree, and blob.
If you zipped up your entire mysite folder right now
and emailed it to me, I could unzip it and make another change to
index.html and commit that change to my local copy on
disk. Let’s say I changed the line to say
<center>Cats are TERRIBLY cute.</center>.
Now I have 9 files in my objects folder. Three more
for the commit I just made, its tree and blob.
I want to share my changes with you. So I zip up the 3 object files you don’t have and email them to you.
Are you ready for this? You take my three object files and just
dump them into your objects folder. You don’t
have to worry at all about overwriting anything, about
losing data, about screwing up your repository, because
we’ve already established that these file names are
completely unique. Wolves in the night, remember?
You’ve just manually performed a git fetch,
which is the safest operation ever because it’s just
collecting someone else’s unique commit files and tossing
them into to your database.
In my email, I’ll say “My latest commit is
3bd54c.” So you type “git checkout 3bd54c" and boom you’re looking at my latest changes.
If we emailed back and forth a lot, I might want to add you as a
remote so that Git does the moving of files around for
me. And I might scribble down the latest commit hash that I got
from you in a file called origin/master or something.
Sound familiar?
Mastery

Octobi Wan Catnobi by
![]()
For me, understanding the structure of the object database was my Eureka moment for Git. After that, I could start to understand not just how Git worked, but why.
The best way to get yourself out of a Git disaster scenario is to understand what Git is trying to do for you.
And when you understand how Git works, your Google Power will
increase tenfold. How did I know to type “git checkout -- .”? Well I just looked online until I found a command that
sounded like it did what I would do myself if I had to
write some code to poke around the object database.
There’s a lot more to grok about Git from here. Merging, rebasing, and staging come to mind. But it’s not so hard now; it’s all just a bunch of fancy shell scripts anyway.


